
AI News
AI ShortsMate Review: Ai Video Generator Full guide
Check this video on YouTube
Check this video on YouTube
The increasing reliance on machine learning models for processing human language comes with several hurdles, such as accurately understanding complex sentences, segmenting content into comprehensible parts, and capturing the contextual nuances present in multiple domains. […]

Check this video on YouTube

The League of Legends 2024 World Championship will be shown via IMAX in the Wanda chain of theaters in China. Yes, gaming is going everywhere. Here’s another example. IMAX will broadcast the tournament in up […]

Check this video on YouTube
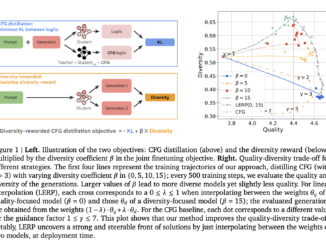
Generative AI models, driven by Large Language Models (LLMs) or diffusion techniques, are revolutionizing creative domains like art and entertainment. These models can generate diverse content, including texts, images, videos, and audio. However, refining the […]

Check this video on YouTube
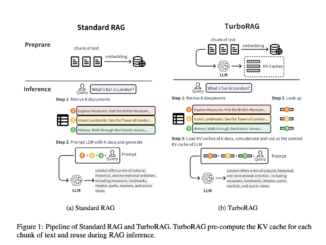
High latency in time-to-first-token (TTFT) is a significant challenge for retrieval-augmented generation (RAG) systems. Existing RAG systems, which concatenate and process multiple retrieved document chunks to create responses, require substantial computation, leading to delays. Repeated […]

Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More By now, large language models (LLMs) like ChatGPT and Claude have become an everyday word across […]
Check this video on YouTube
© Copyright 2026 KryptoGainz.com