AI News
News Groups Ask Apple to Take Down AI Feature. #verity #news #apple #ai #fyp #explore
Check this video on YouTube
Check this video on YouTube

OpenAI is awarding a $1 million grant to a Duke University research team to look at how AI could predict human moral judgments. The initiative highlights the growing focus on the intersection of technology and […]
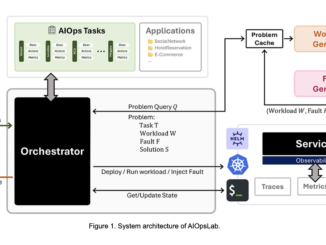
The increasing complexity of cloud computing has brought both opportunities and challenges. Enterprises now depend heavily on intricate cloud-based infrastructures to ensure their operations run smoothly. Site Reliability Engineers (SREs) and DevOps teams are tasked […]

Check this video on YouTube

Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More While the 2024 U.S. election focused on traditional issues like the economy and immigration, its quiet […]
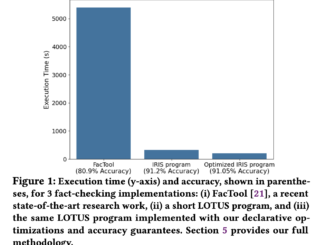
Modern data programming involves working with large-scale datasets, both structured and unstructured, to derive actionable insights. Traditional data processing tools often struggle with the demands of advanced analytics, particularly when tasks extend beyond simple queries […]

Check this video on YouTube

Join our daily and weekly newsletters for the latest updates and exclusive content on industry-leading AI coverage. Learn More Two years on from the public release of ChatGPT, conversations about AI are inescapable as companies […]

The UK Government wants to prove that AI is being deployed responsibly within public services to speed up decision-making, reduce backlogs, and enhance support for citizens. New records, part of the Algorithmic Transparency Recording Standard […]

Check this video on YouTube
© Copyright 2026 KryptoGainz.com