
AI News
#ai #aiart #metal #ironmaiden – 👨: Reasoning guides the path to discovery.
Check this video on YouTube
Check this video on YouTube

Mistral AI has released Mixtral 8x22B, which sets a new benchmark for open source models in performance and efficiency. The model boasts robust multilingual capabilities and superior mathematical and coding prowess. Mixtral 8x22B operates as […]
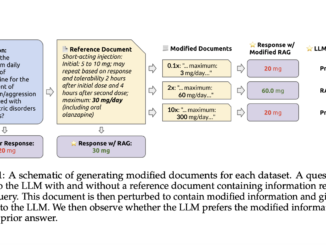
Retrieval-Augmented Generation (RAG) is emerging as a pivotal technology in large language models (LLMs). It aims to enhance accuracy by integrating externally retrieved information with pre-existing model knowledge. This technology is particularly important in addressing […]

Check this video on YouTube

Meta has introduced Llama 3, the next generation of its state-of-the-art open source large language model (LLM). The tech giant claims Llama 3 establishes new performance benchmarks, surpassing previous industry-leading models like GPT-3.5 in real-world […]

The exploration of artificial intelligence within dynamic 3D environments has emerged as a critical area of research, aiming to bridge the gap between static AI applications and their real-world usability. Researchers at Google DeepMind have […]
Check this video on YouTube

SAS, a specialist in data and AI solutions, has unveiled what it describes as a “game-changing approach” for organisations to tackle business challenges head-on. Introducing lightweight, industry-specific AI models for individual licence, SAS hopes to […]

Reinforcement Learning (RL) continuously evolves as researchers explore methods to refine algorithms that learn from human feedback. This domain of learning algorithms deals with challenges in defining and optimizing reward functions critical for training models […]

Check this video on YouTube
© Copyright 2026 KryptoGainz.com