AI News
Beyond the Reference Model: SimPO Unlocks Efficient and Scalable RLHF for Large Language Models
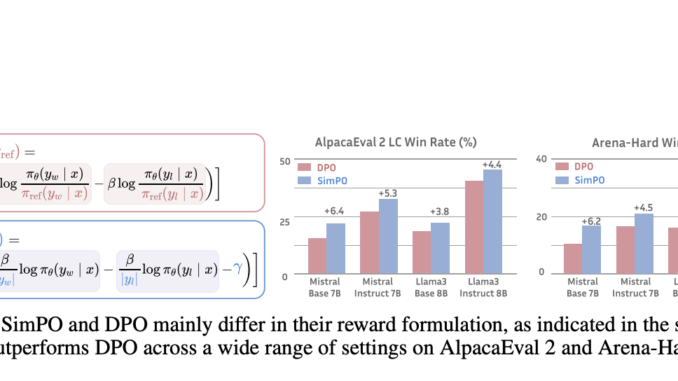
Artificial intelligence is continually evolving, focusing on optimizing algorithms to improve the performance and efficiency of large language models (LLMs). Reinforcement learning from human feedback (RLHF) is a significant area within this field, aiming to […]








